
For a long time now I have been thinking about Web 3.0 – not to join the hype, but to better understand the potential of web developments that will effectively merge thinking in disparate fields.
Unlike some of my colleagues, my thinking (and my blog) bounces between two distinctive fields or disciplines – education and pedagogy vs technology and information science. I think I am lucky, because too often I see the errors of thinking that some educators (and leaders) perpetuate in the guise of keeping up with the (21st century learning) Jones!
 Web 3.0 is getting some blogosphere air-space – and about time too. Adaptive hypermedia research has been around for many years, nicely juxtaposed against developments in search alogorithms and enhancements with various serach engines. A dawn of a new era? Certainly not according to Jean-Noel Jeanneney in his book Google and the Myth of Universal Knowledge. Google’s digitisation project has provided a healthy jolt to our complacency, and the assumption that digital initatives = fantastic developments. Here is the true rub of machine generated, folksonomy driven hierachies where virtual information is being brewed in a global cauldron.
Web 3.0 is getting some blogosphere air-space – and about time too. Adaptive hypermedia research has been around for many years, nicely juxtaposed against developments in search alogorithms and enhancements with various serach engines. A dawn of a new era? Certainly not according to Jean-Noel Jeanneney in his book Google and the Myth of Universal Knowledge. Google’s digitisation project has provided a healthy jolt to our complacency, and the assumption that digital initatives = fantastic developments. Here is the true rub of machine generated, folksonomy driven hierachies where virtual information is being brewed in a global cauldron.
In my view, we should be less interested in the utopian dream of exhaustiveness than in aspiring to the richest, the most intelligent, the best orgainzed, the most accessible of all possible selections. …Jean-Noel Jeanneney
It is time to focus on the cultural and knowledge aspects of Web 2.0 as it moves to Web 3.0, if for no other reason than this digitisation of our society provides challenges and opportunities for equality or repression like never before.
For this discovery of yours will create forgetfulness in the learner’s souls, because they will not use their memories; they will trust to the external written characters and not remember themselves…….PLATO, Paedrus, translated by Benjamin Jowett
Phil Midwinter asks Is Google a Semantic Search Engine, and goes on to explain that Google is using semantic technology, though it is not yet a fully fledged semantic search engine. He is more optimistic about developments.
There are barriers that Google needs to overcome… is it capable of becoming fully semantic without modifying it’s index too drastically; can Google continue to keep the results simple and navigable for its varied user base? Most importantly, does Google intend to become a fully semantic search engine and to do so within a timescale that won’t damage their position and reputation? I like to think that although the dragon is sleeping, that doesn’t mean it’s not dreaming!
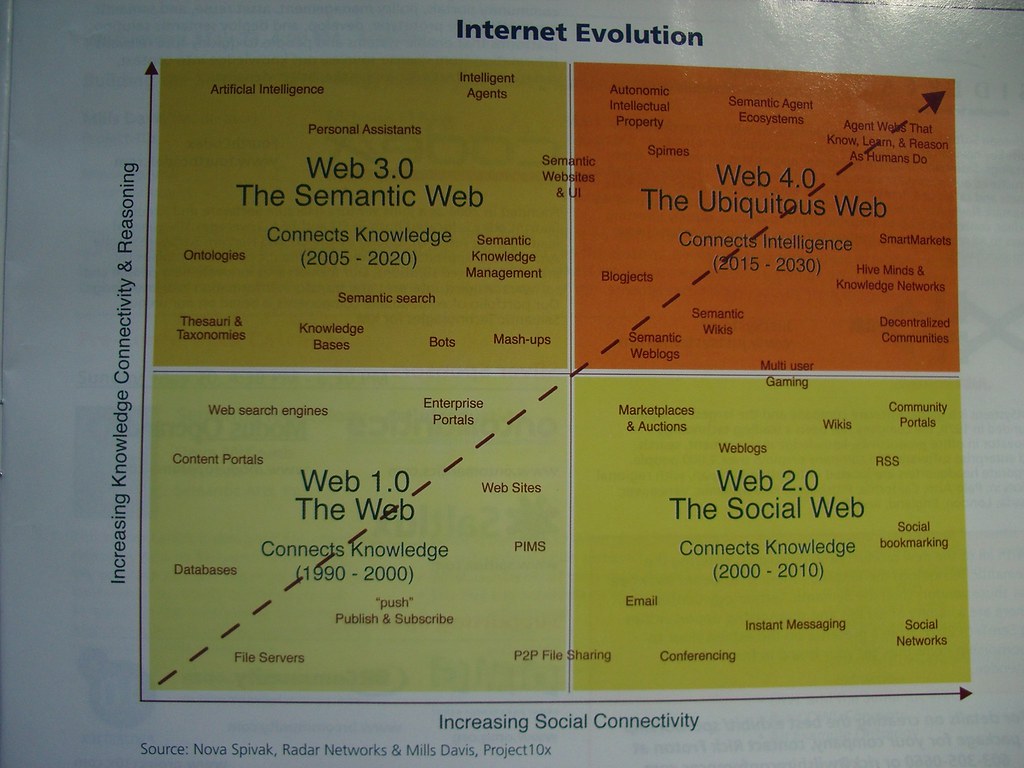
A business-oriented write-up, which nevertheless has important considerations for the educator/information professional. The key thing is that there appears to be a convergence in thinking around the fact that “semantics” will form the backbone of what might be dubbed “Web 3.0”. The Wikipedia entry on Web 3.0 talks of leveraging semantic web for 3-dimensional collaboration…even as far as to point to this as being on the evolutionary path to artificial intelligence! (the stuff of many SciFi stories)
However, what we are really needing to examine closely, is the rise of the API culture – as this is transforming what it is we can seek or serve our knowledge-seeking selves!
Read/Write Web to the rescue! Another excellent write-up from Alex Iskold on Web 3.0: When Web Sites Become Web Services. Well, I suggest that we need to do a lot of reading and learning about folksonomy and taxonomy … and more. Let’s say, more posts for another day.
BUT what we do know already is that the Semantic Web efforts are providing an approach to constructing flexible, intelligent information systems – and it is the synergies between ubiquity and semantics that are exciting, and in which we should expect to see significant future work.
Read more about this in Embracing “Web 3.0” in IEEE Internet Computing.
Technorati Tags: semantic web, web services, IEEE, google, Jean-Noel Jeanneney,
